Trier, classer, ranger, ordonner
Levons tout d'abord quelques ambiguïtés par rapport à ces quatre mots :
- Trier veut dire qu'on retient certains éléments en fonction de certains critères et qu'on élimine les autres;
- Classer veut dire qu'on va faire des catégories et y ranger les éléments en fonction de certains critères;
- Ranger et ordonner sont synonymes, il s'agit de d'organiser l'ensemble des éléments selon un ou plusieurs critères.
En ce qui nous concerne, les critères des « tris » que nous allons effectuer seront essentiellement le rangement alphabétique et l'ordre numérique.
Trois méthodes de tri
Il existe de nombreuses méthodes de tri, une recherche sur l'Internet aura vite fait de vous en convaincre. Notre but n'est pas d'être exhaustif à ce niveau, nous allons nous restreindre à deux méthodes couramment utilisées et une méthode simplifiée :
- Le tri à bulles;
- Le tri par sélection;
- Le tri simplet (le moins rationnel des 3, mais le plus simple à mette en œuvre).
A. Le tri simplet
Nous allons commencer par celui-là, qui est une espèce de « mélange » des deux autres mais qui nous permettra de mieux les comprendre et qui est plus facile à aborder au niveau de l'algorithmique.
Le principe en est très simple :
- On balaie le tableau case par case en comparant son contenu à celui de la case suivante;
- Si le contenu de gauche est plus grand que celui de droite (tri croissant), on permute les contenus;
- On recommence le balayage jusqu'à ce qu'il n'y ait plus aucune permutation durant le balayage, signe que le tableau est bien ordonné.
Reste à organiser tout cela en code JS, cela va ressembler à ceci pour le tri croissant (de nombres ou de mots, peu importe) de la variable « tableau » comportant 5 cases numérotées de 0 à 4.

- - ligne 1, on remplit directement la variable indicée « tableau » avec son contenu;
- - Ligne 2, la boucle provoque le recommencement du processus de tri tant qu'il y a eu au moins une permutation, signe que le tableau n'est pas encore tout à fait rangé;
- - Ligne 4, le signal d'une permutation est remis à faux au moment où on recommence à balayer le tableau (voir le tour de main du signal dans le chapitre suivant);
- - Ligne 5, la boucle for du balayage ne va que de 0 à 3 car on compare avec la case suivante. Si on allait jusqu'à 4, on comparerait avec une case qui n'existe pas;
- - Ligne 6, on teste si le contenu de la case de gauche est supérieur à celui de la case de droite, si c'est le cas, on va permuter. Si l'on voulait un classement par ordre décroissant, il suffirait de remplacer le > par <;
- - Lignes 8 à 10, si on veut permuter sans écraser une donnée, il faut faire une rotation à 3 : une variable annexe accueille une donnée pendant qu'elle est écrasée par la donnée arrivant de la case adjacente;
- - Ligne 11, la variable signalant qu'il y a eu une permutation est mise à vrai... et le tour est joué, les balayages et permutations vont s'enchaîner jusqu'à ce que le tableau soit bien rangé;
- - les lignes 14 et 15 sont accessoires, elles permettent l'affichage du contenu du tableau pour vérification.
Voici ce qui se passe lors du premier balayage pour les différentes valeurs prises par la variable i de la boucle for :





À la fin de la première boucle de balayage, on constate que la valeur la plus élevée (Séb) se retrouve directement dans la dernière case du tableau. Il ne serait donc plus nécessaire, lors du balayage suivant, d'aller jusqu'au bout du tableau. C'est pourtant ce que fait cette méthode et c'est du temps perdu. La méthode de tri suivante corriger cela.
B. Le tri à bulles
Cette méthode va gagner en rationalité car, au lieu de balayer chaque fois jusqu'à la dernière case, chaque nouveau balayage va s'arrêter une case plus tôt. Malheureusement, cela va compliquer un peu les choses au niveau du script...
Cette méthode va utiliser deux boucles for imbriquées, la première (trait rouge) remontant de la fin du tableau vers le début et la seconde (flèche verte) en ne balayant, à chaque tour, que du début du tableau à la limite fixée par la première boucle.
Voici le schéma de ce processus.




Ce qui peut être mis en œuvre par le script suivant (remarquez que la variable booléenne signalant les permutations est devenue inutile) :

Quelques explications :
- Ligne 2, la variable j (le trait rouge) remonte de la limite du tableau (ici l'indice 4) jusqu'à la case 1 (il restera les cases 0 et 1 à comparer);
- Ligne 3, la variable i (la flèche verte) descend de la case 0 jusqu'à la case j-1 du fait de la comparaison avec la case suivante, qui doit exister;
- Ligne 4, au cas où les données des deux cases adjacentes ne sont pas dans le bon ordre, on permute.
C. Le tri par sélection
Le tri par sélection utilise une autre technique :
- Une première boucle va sélectionner les cases en partant de la première jusqu'à l'avant-dernière;
- Pour chacune des cases sélectionnées par la première boucle (appelée case de référence), une seconde boucle va vérifier dans les cases suivantes s'il n'y a pas une valeur plus petite (pour un tri croissant) que la valeur de la case de référence;
- Si c'est le cas, il y aura permutation des contenus des deux cases.




Cette méthode sera mise en œuvre par le script suivant :

Script qui mérite quelques explications :
- Ligne 1, la variable supplémentaire min est déclarée, elle est destinée à acceuillir l'indice de la case contenant la valeur la moins élevée (tri croissant) lors du balayage de la seconde boucle (i);
- Ligne 2, j va balayer de la première case à l'avant-dernière case du tableau;
- Ligne 4, min est affectée avec l'indice de la case de référence, à savoir la valeur j;
- Ligne 5, i va balayer de la case qui suit la case j jusqu'à la dernière case du tableau;
- Ligne 6, si la valeur contenue dans la case i du tableau est inférieure à la valeur de la case contenant actuellement la valeur la plus petite (min), l'indice min est mis à jour avec le nouveau i;
- Ligne 8, si la valeur contenue dans min est différente de la valeur de référence j, c'est qu'on a trouvé une valeur plus petite dans la seconde boucle de balayage. On va alors permuter les valeurs contenues dans les cases numéros min (valeur la plus petite trouvée) et j (case de référence).
Ta tâche, ton défi
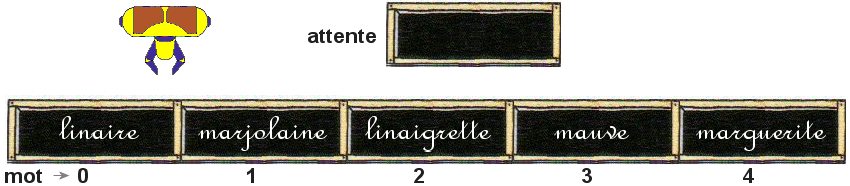
Fais en sorte que le robot classe ces 5 mots par ordre alphabétique
Le robot dispose de deux variables : mot qui est un tableau et qui contient les mots affichés dans les ardoises ci-dessus et attente qui est la variable qui permettra la permutation.
Pour réaliser sa tâche, le robot dispose des 3 fonctions d'actions :
- copieVersAttenteDeMot (x); où x est l'indice de la case de mot dont le contenu est à copier dans attente;
- copieDeAttenteVersMot (x); où x est l'indice de la case de mot dans laquelle le contenu de attente doit être copié;
- copieDeMotVersMot (source, destination); qui permet de copier le contenu de la case source de mot dans la case destination de mot.
Remarque : les indices mentionnés ci-dessus peuvent être des valeurs numériques telles que 1, 2,... ou des expressions numériques telles que i+1,...
Pour effectuer ce tri, tu peux utiliser la méthode ci-dessus qui te plaît le plus ou une autre méthode de ton choix.
Bonne réalisation.